
Sound Recognition
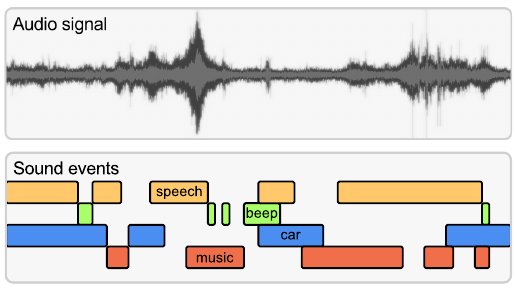
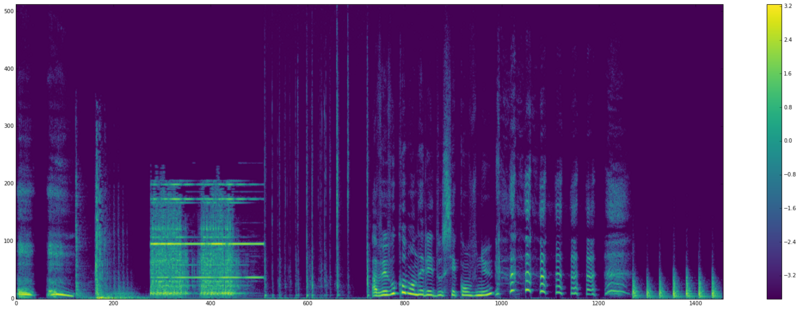
Motivation
Sounds carry a lot of information in our everyday environment, be it in a traffic environment, where we can recognize sounds from cars nearby or an ambulance siren, or a home environment with sounds such as laughter, a fire alarm, or glas breaking. Every audio event conveys a certain meaning and may have an important impact on its surroundings. Therefore there is a rising interest in intelligent systems that are able to recognize sounds. Possible applications are, e.g., the retrieval of multimedia content, autonomous driving and monitoring systems for traffic, smart homes and public areas, to name a few. While humans can usually recognize various sounds and act accordingly, the development of signal processing and machine learning methods to recognize sounds embedded in acoustic signals is still in its nascent stages.
Challenges
Driven by the annual DCASE (Detection and Classification of Acoustic Sounds and Events) series of challenges and the availability of large-scale databases, the state-of-the-art has emerged rapidly in recent years with Deep Neural Networks (DNNs) dominating the field. However, there are still many challenges and open problems which are far from being solved. Compared to speech processing, for example, general sounds have much larger variability (in fact speech is a subclass of general sounds). Also, there is not only a huge number of different sounds but also many different environments they may appear in. Moreover, data labelling is expensive and time-consuming which is why labelled data is scarce. Therefore it is hard to find training data, which is labelled and matches the application scenario.
Topics
Topics we are working on include, but are not limited to:
- Sound recognition on Acoustic Sensor Networks (ASNs)
- Sound recognition with mismatched training data
- Weakly supervised sound event detection
- System training with error-prone labels
- Anomaly detection
- Unsupervised sound event discovery

