
Deep Generative Models for Research in Phonetics
Deep learning has revolutionized many areas in recent years. For example, deep neural networks can be used to synthesize speech from text input that can hardly be distinguished from natural speech. In two projects, we are developing methods to perform targeted modifications of phonetically relevant features in a speech signal and investigate their suitability for phonetics research.
Phonetics is the science of spoken language. Among other things, it deals with the acoustic features that encode certain para- or extralinguistic phenomena. For this purpose, speech samples are collected from test persons and scrutinized. However, a recurring problem is that the speech signal is influenced by many factors, such as speaker characteristics, environmental influences, and the content of what is said. That makes it extremely difficult to isolate the effect on the speech signal caused by the particular factor one is interested in.
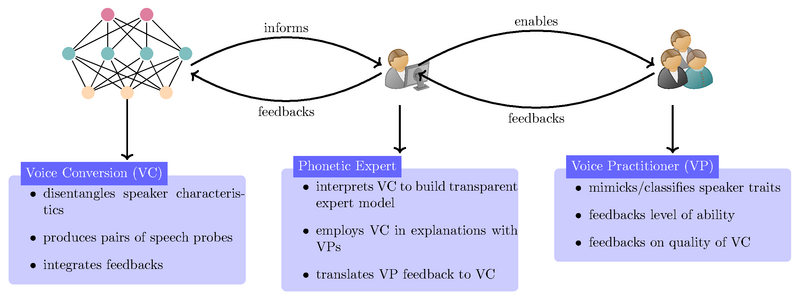
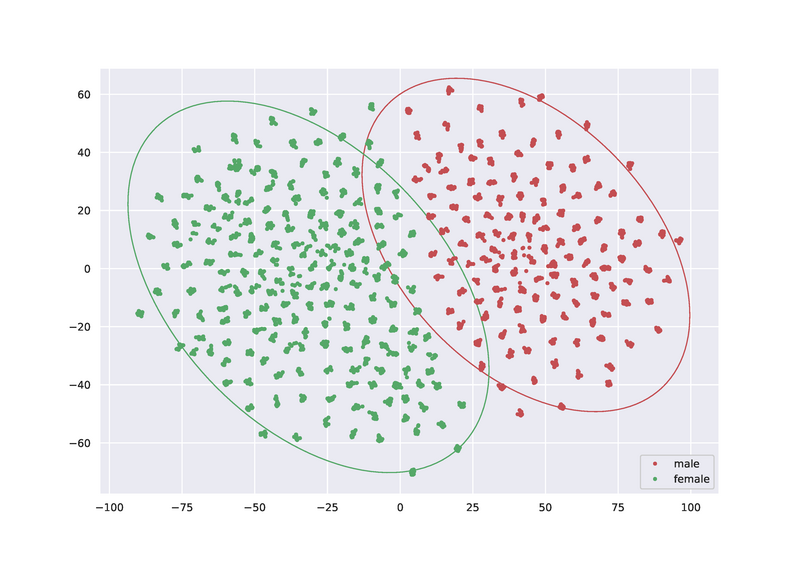
This is where our research comes in. Within the projects "Deep Phonetics" (DFG 446378607) and "Constructing Explainability" (TRR 318), we collaborate with phoneticians at Bielefeld University who contribute the necessary expert knowledge in phonetics to assess voice quality. We have developed a system for disentangling the variations in the speech signal based on the voice chararcteristics of the speaker from those caused by the content of what is spoken. This allows us to study the voice quality of the speaker regardless of the content of the sentence. For example, one dimension in the space of speaker features allows an almost perfect separation into male and female speakers (Figure "pyhtonplots.eps"). Further, voice conversion can be performed by exchanging the speaker properties with those of another speaker. This produces speech samples with identical content but different vocal characteristics, which are particularly useful for exploring acoustic realizations of perceptual properties of speech.
Synthesized speech samples help experts to explain phonetic phenomena
Detecting disease patterns based on voice quality is an area of research in clinical linguistics. However, there is no objective measure for assessing voice quality: the evaluation is subjective and based on experience. This often leads to errors and inconsistencies in the assessment. This is where voice conversion systems can help to imprint or remove certain voice qualities from a speech signal. Using the speech samples synthesized in this way, an expert can clearly explain the characteristics of different perceptual voice qualities to clinical linguists. At the same time, the expert's feedback serves to improve the naturalness of the synthesized speech samples.

