
Tiefe generative Modelle für die Phonetikforschung
Deep Learning hat in den letzten Jahren viele Bereiche revolutioniert. So kann man mit tiefen neuronalen Netzen gesprochene Sprache aus Texteingabe synthetisieren, die kaum noch von natürlicher Sprache zu unterscheiden sind. Im Rahmen zweier Projekte entwickeln wir Verfahren, um eine gezielte Modifikation phonetisch relevanter Merkmale in einem Sprachsignal durchzuführen und untersuchen deren Tauglichkeit für die Phonetikforschung.
Die Phonetik ist die Wissenschaft von der gesprochenen Sprache. Sie beschäftigt sich unter anderem damit, durch welche akustischen Merkmale bestimmte para- oder extralinguistische Phänomene encodiert werden. Dazu werden Sprachproben von Probanden gesammelt und untersucht. Problematisch ist dabei, dass verschiedene Einflussfaktoren das Sprachsignal bestimmen, wie etwa Sprechercharakteristika, Umwelteinflüsse und der Inhalt des Gesprochenen, die nicht leicht voneinander zu trennen sind, um ein einzelnes Phänomen zu untersuchen.
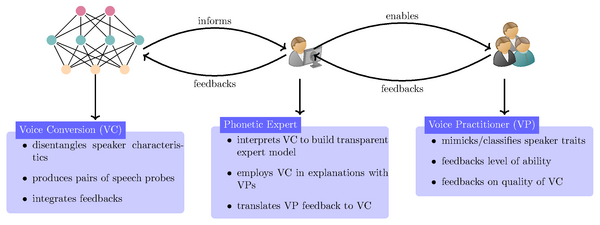
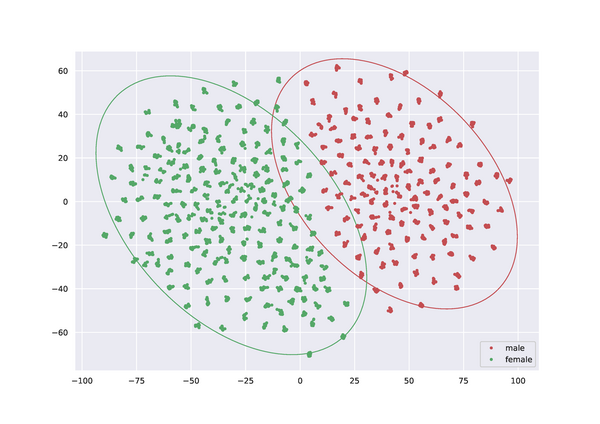
Hier setzt unsere Forschung an. Im Rahmen der Projekte “Deep Phonetics” (DFG 446378607) und “Constructing Explainability” (TRR 318) arbeiten wir mit Phonetikern der Universität Bielefeld zusammen, die das nötige Expertenwissen zur Bewertung von Stimmqualität beisteuern. Wir haben ein System zur Entflechtung der Variationen im Sprachsignal aufgrund der Stimmqualität des Sprechers und zum anderen aufgrund des Inhalts des Gesprochenen entwickelt. Dadurch können wir die Stimmqualität des Sprechers ungeachtet des Satzinhalts untersuchen. Beispielsweise erlaubt eine Dimension im Raum der Sprechereigenschaften eine fast perfekte Trennung in männliche und weibliche Sprecher (Abbildung „pyhtonplots.eps“). Weiter lässt sich durch Austauschen der Sprechereigenschaften mit denen eines anderen Sprechers eine Stimmenkonvertierung durchführen. Damit werden Sprachproben mit identischem Inhalt aber unterschiedlichen stimmlichen Charakteristika erzeugt, die sich besonders gut zur Erforschung von akustischen Realisierungen von perzeptiven Eigenschaften der Sprache eignen.
Synthetisierte Sprachproben helfen Experten bei der Erklärung
Die Erkennung von Krankheitsbildern anhand der Stimmqualität ist ein Forschungsgebiet in der klinischen Linguistik. Allerdings gibt es für die Beurteilung der Stimmqualität kein objektives Maß: Die Beurteilung ist subjektiv und beruht auf Erfahrung. Dies führt häufig zu Fehlern und Inkonsistenzen in der Bewertung. Hier können Systeme zur Stimmenkonvertierung helfen, um Stimmqualitäten auf das Sprachsignal aufzuprägen oder zu entfernen. Anhand der so synthetisierten Sprachproben kann eine Expertin den klinischen Linguisten die Eigenschaften verschiedener Stimmqualitäten anschaulich erklären. Zugleich dient das Feedback des Experten zur Verbesserung der Natürlichkeit der synthetisierten Sprachproben.

